Table of Contents
Real Time Data Loader
In this document you'll find a guide to configure a kafka environment with the respective mongo db connectors and all you need to run a real time data loader in your local environment.
Pre-requisites
- Docker installed with docker-compose command enabled.
- Atlas Cluster running with the proper databases and collections.
- A user with readWrite and changeStream roles for the Atlas Cluster.
- In Windows you'll need a git bash or some other Linux-based shell to run the script.
Kafka Setup
If you already have a kafka service running you can ignore this section.
Step by step guide
- Locate the start-kafka.sh script at the scripts folder in this repo.
- Run the run.sh script with the respective parameters in your shell
./start-kafka.sh --mongo-uri "mongodb+srv://<username:password>@<yourcluster>.mongodb.net/" --database "<your-database>" --collection "<your-collection>" --kafka-bootstrap-servers "localhost:9092" --sink_topic "<sink_topic_name>" --source_topic "<source_topic_name>"
- OPTIONAL: Configure your own connectors. You can create additional connectors to monitor other collections (source) or send data to your database from other topics (sink).
For Linux
Note: The topics for those connector must be different. Example: userAvailable for sink connector and intermediateTopic for source connector. The topic used at the source connector is the one that the RTDL is going to use to listen to messages.
Sink Connector. Configure <your_atlas_uri>, <your_database>, <your_collection>, <your_topic> and
the kafka.bootstrap.servers if you're using a different kafka deployment.
curl -X POST -H "Content-Type: application/json" --data '
{
"name": "mongodb-sink-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"connection.uri": "<your_atlas_uri>",
"database": "<your_database>",
"collection": "<your_collection>",
"topics": "<your_topic>",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"mongo.errors.tolerance": "data",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "mongoerror",
"errors.deadletterqueue.topic.replication.factor": 1,
"kafka.bootstrap.servers": "localhost:9092"
}}' http://localhost:8083/connectors -w "\n"
Source Connector. Configure <your_atlas_uri>, <your_database>, the topic.namespace.map following the pattern and
displayed in the example and the kafka.bootstrap.servers if you're using a different kafka deployment.
curl -X POST -H "Content-Type: application/json" --data '
{
"name": "mongodb-maap-data-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSourceConnector",
"connection.uri": "<your_atlas_uri>",
"database": "<your_database>",
"topic.namespace.map": "{\"<your_database>.<your_collection1>\": \"<your_topic1>\", \"<your_database>.<your_collection2>\": \"<your_topic2>\", \"<your_database>.<your_collectionN>\": \"<your_topicN>\"}",
"copy.existing": true,
"poll.max.batch.size": 100,
"poll.await.time.ms": 5000,
"kafka.bootstrap.servers": "localhost:9092",
"tasks.max": "1",
"heartbeat.interval.ms": 3000,
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"auto.offset.reset": "latest",
"enable.auto.commit": true,
"acks": "all",
"pipeline": "[{\"$match\": {\"operationType\": {\"$in\": [\"insert\", \"update\", \"replace\"]}}}]"
}}' http://localhost:8083/connectors -w "\n"
For Windows
Create 1 json file for each connector anywhere in your computer:
Configure <your_atlas_uri>, <your_database>, <your_collection>, <your_topic> and the kafka.bootstrap.servers if you're using a different kafka deployment.
Note: The topics for those connector must be different. Example: userAvailable for sink connector and intermediateTopic for source connector. The topic used at the source connector is the one that the RTDL is going to use to listen to messages.
Sink Connector
{
"name": "mongodb-sink-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"connection.uri": "<your_atlas_uri>",
"database": "<your_database>",
"collection": "<your_collection>",
"topics": "<your_topics>",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"mongo.errors.tolerance": "data",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "mongoerror",
"errors.deadletterqueue.topic.replication.factor": 1,
"kafka.bootstrap.servers": "localhost:9092"
}
}
Source Connector
{
"name": "mongodb-maap-data-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSourceConnector",
"connection.uri": "<your_atlas_uri>",
"database": "<your_database>",
"topic.namespace.map": "{\"<your_database>.<your_collection1>\": \"<your_topic1>\", \"<your_database>.<your_collection2>\": \"<your_topic2>\", \"<your_database>.<your_collectionN>\": \"<your_topicN>\"}",
"copy.existing": true,
"poll.max.batch.size": 100,
"poll.await.time.ms": 5000,
"kafka.bootstrap.servers": "localhost:9092",
"tasks.max": "1",
"heartbeat.interval.ms": 3000,
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"auto.offset.reset": "latest",
"enable.auto.commit": true,
"acks": "all",
"pipeline": "[{\"$match\": {\"operationType\": {\"$in\": [\"insert\", \"update\", \"replace\"]}}}]"
}
}
Run the following command in powershell:
Invoke-WebRequest -Uri "http://localhost:8083/connectors" -Method Post -Headers @{ "Content-Type" = "application/json" } -InFile "path\to\your\config_files.json"
Note: the -Uri is pointing to your connectors endpoint, change it for the one pointing to your connectors endpoint.
Data Loader
This data loader is used to receive messages in real time from a Kafka topic. The ingest runs indefinitely until the process is stopped manually. Everytime a message is received, it looks for the content that is meant to be processed makes an entry into the configured database.
Usage:
ingest:
- source: 'realtime'
topic: 'source-connector-topic'
brokers: ['localhost:9092']
fields: ['field1', 'field2', 'fieldN']
thumblingWindow: 6000
chunk_size: 600
chunk_overlap: 60
Architecture:
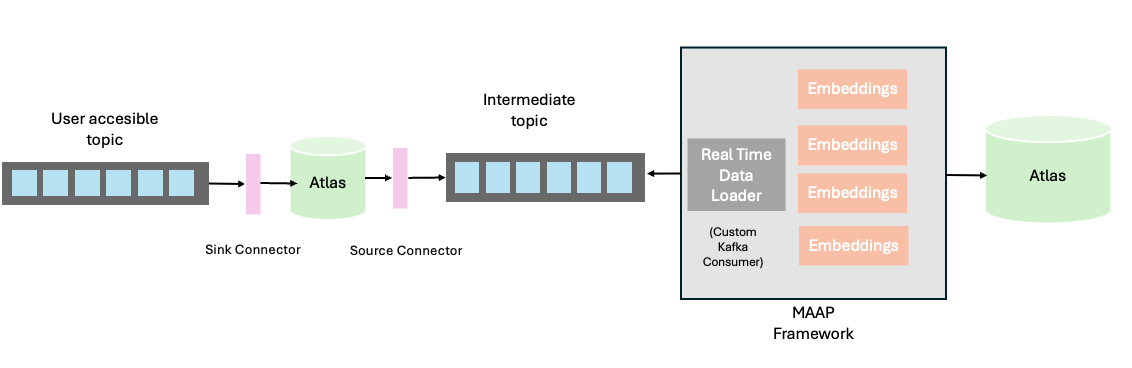
Expected format for Sink topic messages
The only required field is the content field, the rest of fields are going to be set as metadata for the metadata field in the main db.
{"content": "Plain text goes here. It could be loooong…", "metadata1":"value1", "metadata2":"value2", "metadataN":"valueN"}
Example:
{"database_collection": "StreamData", "content": "Plain text goes here. It could be loooong…", "title": "Test Text", "created": "2021-11-17T03:19:56.186Z"}
Test
Download kafka in your computer local computer: https://kafka.apache.org/downloads
Unzip the folder content and go to the bin folder in a console. For Linux run the .sh command, for Windows go one level deeper to the folder called windows and run the equivalent .bat
Run
./kafka-console-producer.sh --broker-list localhost:9092 --topic <your_sink_connector_topic>
Send a message with the appropriate json format (described before).
Expected behaviour (as described in the architecture)
- The sink connector uploads the file inserted into the atlas database. (This works for any insertion with the proper format into this topic, not only from console)
- The source connector detects that a file has been inserted into the collection. (This works with direct insertions too).
- MAAP receives the message in the source topic and extracts the content.
- MAAP creates the embeddings and writes to the final database.