Temporal
The MongoDB - Temporal Quickstart is an integrated end-to-end AI application framework that combines MongoDB Atlas, Amazon Bedrock, and Temporal Workflow technology. The system provides a conversational AI interface with advanced memory capabilities, semantic caching, and robust document processing abilities.
Table of Contents
- System Overview
- Architecture
- Services in Detail
- Workflows
- MCP (Model Context Protocol)
- MongoDB Integration
- Installation & Deployment
- API Reference
- Usage Flow
- Error Handling and Logging
- Security Considerations
- Monitoring & Logging
- Troubleshooting
- Scalability Considerations
- Development Guide
- Maintenance & Operations
- Conclusion
1. System Overview
The architecture features multiple microservices communicating through a Temporal workflow orchestration layer, which ensures reliability, fault tolerance, and scalability. The system leverages MongoDB Atlas for vector database capabilities, Amazon Bedrock for AI services (embeddings and LLMs), and Temporal for workflow orchestration.
Key features include:
- Vectorized document storage and retrieval using MongoDB Atlas
- Hybrid search combining vector similarity and keyword matching
- AI-powered conversation and memory management
- Workflow orchestration using Temporal
- Integration with AWS Bedrock for AI model inference
- Semantic caching for improved response times
- AI-augmented memory for contextual responses
- Data loading and processing from various sources
- Image processing capabilities
- Event logging and monitoring
- Scalable and maintainable microservices architecture
2. Architecture
The system architecture diagram for MongoDB - Temporal Quickstart:
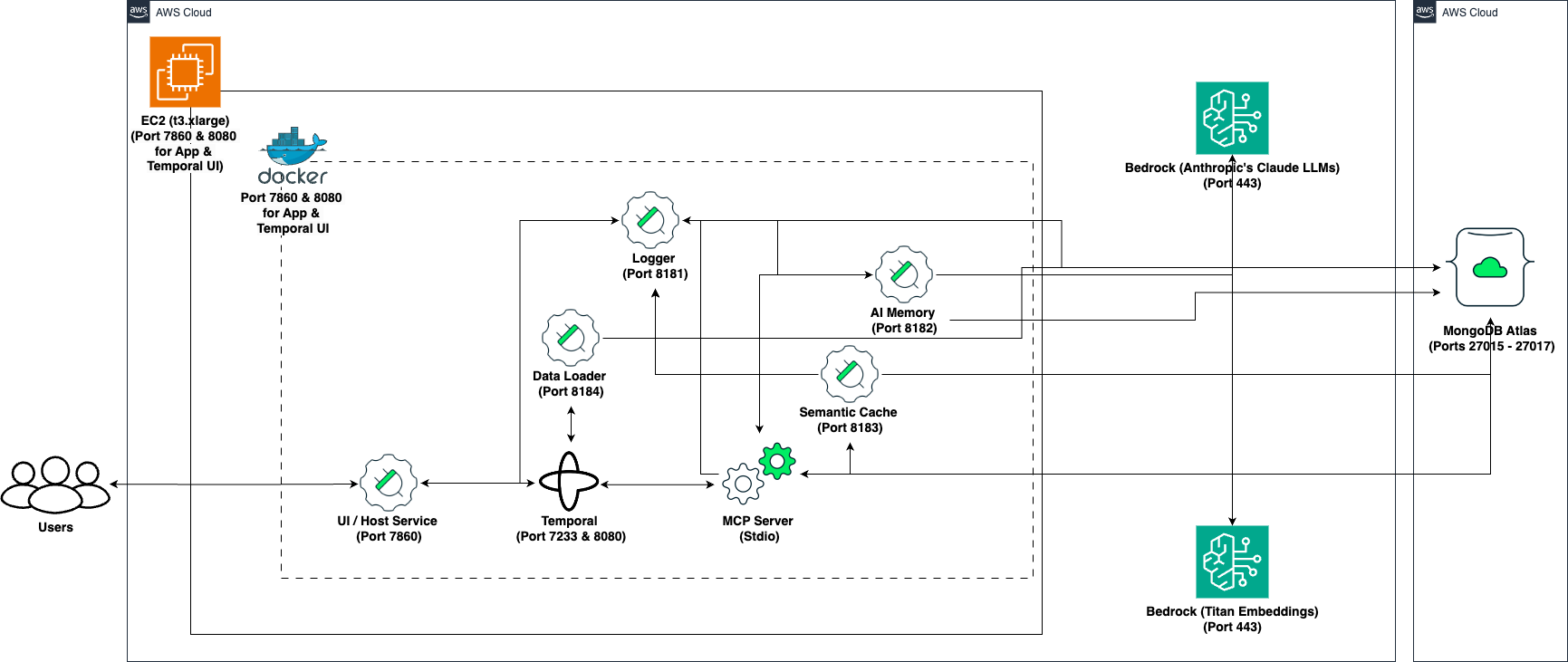
The diagram illustrates the MongoDB - Temporal system architecture with:
- User Interface: The entry point for user interactions
- FastAPI/Gradio Application: The web application layer providing the UI and API endpoints
- Temporal Workflow Engine: Orchestrates workflows and activities
- MCP Clients Manager: Central manager for Model Context Protocol clients
- Service Components:
- MongoDB Service: Handles database operations
- Bedrock Service: Manages AI model interactions
- AI Memory Service: Provides conversation history and memory functions
- Semantic Cache Service: Caches AI responses for similar queries
- Data Loader Service: Ingests documents and web content
- Event Logger Service: Centralized logging
- Image Processing: Handles image uploads and processing
- External Systems:
- MongoDB Atlas: Vector database for data storage
- AWS Bedrock: AI models for embeddings and text generation
- Logging Service: Central logging facility for application monitoring
2.1 Core Components
The system consists of the following microservices:
- Host Service: The central coordinator that manages the UI and workflow orchestration (Port 7860)
- AI Memory Service: Provides conversation history and memory functions (Port 8182)
- Semantic Cache Service: Caches AI responses for similar queries (Port 8183)
- Data Loader Service: Ingests and processes documents and web content (Port 8184)
- Event Logger Service: Centralized logging service (Port 8181)
- Temporal Service: Workflow orchestration and execution (Port 7233 & 8080)
2.2 Integration Points
- MongoDB Atlas: Vector database for storing embeddings, documents, and conversational data (Ports 27015 to 27017 (TCP))
- Amazon Bedrock: Provides AI capabilities through Claude and Titan models (Port 443)
- Temporal: Workflow orchestration system for reliable workflow execution (Port 7233 & 8080)
- Docker & Containers: All services are containerized for deployment
3. Services in Detail
3.1 Host Service
The Host Service serves as the central coordinator and provides:
- User interface via Gradio
- Temporal workflow client
- MCP (Model Context Protocol) server for tool integration
- Workflow definitions and activity implementations
Key Files:
host/ui_app.py: Main UI applicationhost/temporal_client.py: Temporal client interfacehost/workflows.py: Workflow definitionshost/activities.py: Activity implementationshost/temporal_worker.py: Temporal worker implementationhost/maap_mcp/: MCP server implementation
3.2 AI Memory Service
The AI Memory Service manages conversation history and memory, featuring:
- Long-term memory capabilities for AI
- Hierarchical memory with importance-based retrieval
- Vector-based similarity search for relevant memories
- Conversation summarization
Key Files:
ai-memory/main.py: API endpointsai-memory/services/memory_service.py: Memory management functionsai-memory/services/conversation_service.py: Conversation handlingai-memory/services/bedrock_service.py: AI model integration
3.3 Semantic Cache Service
The Semantic Cache Service provides:
- Vector-based caching of AI responses
- Similarity-based retrieval of cached responses
- TTL-based cache expiration
- User-specific cache entries
Key Files:
semantic-cache/main.py: API endpointssemantic-cache/services/cache_service.py: Cache operationssemantic-cache/services/bedrock_service.py: Embedding generationsemantic-cache/database/mongodb.py: MongoDB integration
3.4 Data Loader Service
The Data Loader Service provides document ingestion and processing:
- File upload and processing
- Web page content extraction
- Document chunking and embedding
- MongoDB vector storage integration
Key Files:
data-loader/main.py: API endpointsdata-loader/services/document_service.py: Document processingdata-loader/services/embedding_service.py: Vector embedding generationdata-loader/utils/file_utils.py: File handling utilities
3.5 Event Logger Service
The Event Logger Service offers:
- Centralized logging for all services
- Structured logging with context
- MongoDB persistence of logs
- Real-time and async log processing
Key Files:
event-logger/main.py: API endpointsevent-logger/logger.py: Logger implementationevent-logger/models/pydantic_models.py: Log data models
4. Workflows
The system uses Temporal workflows to coordinate complex operations reliably. Key workflows include:
4.1 Image Processing Workflow
Handles image uploads and prepares them for AI model consumption.
@workflow.defn
class ImageProcessingWorkflow:
@workflow.run
async def run(self, params: ImageProcessingParams) -> ImageProcessingResult:
# Process image and return result
4.2 Semantic Cache Workflow
Checks if a semantically similar query exists in the cache.
@workflow.defn
class SemanticCacheCheckWorkflow:
@workflow.run
async def run(self, params: SemanticCacheParams) -> Dict[str, Any]:
# Check cache for similar queries
4.3 Memory Retrieval Workflow
Retrieves relevant memories for the current conversation.
@workflow.defn
class MemoryRetrievalWorkflow:
@workflow.run
async def run(self, params: MemoryRetrievalParams) -> Dict[str, Any]:
# Retrieve relevant memories
4.4 AI Generation Workflow
Generates AI responses using Amazon Bedrock.
@workflow.defn
class AIGenerationWorkflow:
@workflow.run
async def run(self, params: AIGenerationParams) -> Any:
# Generate AI response using Bedrock
4.5 Data Ingestion Workflow
Processes and stores documents in the vector database.
@workflow.defn
class DataIngestionWorkflow:
@workflow.run
async def run(self, params: DataIngestionParams) -> Dict[str, Any]:
# Process and store documents
5. MCP (Model Context Protocol)
The system uses a Model Context Protocol implementation for tool integration with the AI model. Key features:
- Tool registration and discovery
- Tool execution with error handling
- Prompt template management
- Resource access
Available Tools:
hybrid_search: Vector-based document searchstore_memory: Store conversation messagesretrieve_memory: Get relevant conversation contextsemantic_cache_response: Cache AI responsescheck_semantic_cache: Check for cached responsessearch_web: Web search using Tavily API
6. MongoDB Integration
6.1 Collections and Indexes
The system uses several MongoDB collections:
- documents: Stores processed documents with vector embeddings
- conversations: Stores conversation messages with timestamps
- memory_nodes: Stores hierarchical memory nodes
- cache: Stores semantic cache entries
- logs: Stores application logs
Vector search indexes are created for similarity-based queries.
6.2 Vector Search
The system uses MongoDB Atlas Vector Search for similarity queries with indexes on:
- Document embeddings
- Memory embeddings
- Conversation embeddings
- Cache entry embeddings
7. Installation & Deployment
7.1 Environment Setup
The system requires:
- MongoDB Atlas cluster
- AWS credentials for Bedrock access
- Docker and Docker Compose
7.2 Configuration Files
Each service has its own .env file for configuration:
- MongoDB Configuration:
MONGODB_URI: Connection stringDB_NAME: Database name
- AWS Configuration:
AWS_REGION: AWS regionAWS_ACCESS_KEY_ID: Access keyAWS_SECRET_ACCESS_KEY: Secret keyEMBEDDING_MODEL_ID: Model for embeddingsLLM_MODEL_ID: Model for text generation
- Service Configuration:
SERVICE_HOST: Host addressSERVICE_PORT: Port numberLOGGER_SERVICE_URL: URL for logging service
7.3 Deployment Scripts
The system provides several scripts for deployment:
build-push-images-to-ecr.ksh: Build and push container images to Amazon ECRmongodb_cluster_manager.ksh: Manage MongoDB Atlas clustersone-click.ksh: One-click deployment using CloudFormationbuild-images.ksh: Build Docker images locallydocker-compose.yml: Docker Compose configuration
Prerequisites
- AWS account with appropriate permissions
- MongoDB Atlas account with appropriate permissions
- Python 3.10+
- Docker and Docker Compose installed
- AWS CLI installed and configured
- EC2 quota for
t3.xlarge - Programmatic access to your MongoDB Atlas project
MongoDB Atlas Programmatic Access
To enable programmatic access to your MongoDB Atlas project, follow these steps to create and manage API keys securely:
1. Create an API Key
- Navigate to Project Access Manager:
- In the Atlas UI, select your organization and project.
- Go to Project Access under the Access Manager menu.
- Create API Key:
- Click on the Applications tab.
- Select API Keys.
- Click Create API Key.
- Provide a description for the key.
- Assign appropriate project permissions by selecting roles that align with the principle of least privilege.
- Click Next.
- Save API Key Credentials:
- Copy and securely store the Public Key (username) and Private Key (password).
- Important: The private key is displayed only once; ensure it's stored securely.
2. Configure API Access List
- Add Access List Entry:
- After creating the API key, add an IP address or CIDR block to the API access list to specify allowed sources for API requests.
- Click Add Access List Entry.
- Enter the IP address or click Use Current IP Address if accessing from the current host.
- Click Save.
- Manage Access List:
- To modify the access list, navigate to the API Keys section.
- Click the ellipsis (...) next to the API key and select Edit Permissions.
- Update the access list as needed.
3. Secure API Key Usage
- Environment Variables: Store API keys in environment variables to prevent hardcoding them in your application's source code.
- Access Controls: Limit API key permissions to the minimum required for your application's functionality.
- Regular Rotation: Periodically rotate API keys and update your applications to use the new keys to enhance security.
- Audit Logging: Monitor API key usage through Atlas's auditing features to detect any unauthorized access.
By following these steps, you can securely grant programmatic access to your MongoDB Atlas project, ensuring that your API keys are managed and utilized in accordance with best practices. For more detailed information, refer to Guide.
Minimum System Requirements
- Sufficient CPU and memory for running Docker containers
- Adequate network bandwidth for data transfer and API calls
- For EC2: At least a
t3.mediuminstance (or higher, depending on workload) - Sufficient EBS storage for EC2 instance (at least 100 GB recommended)
- MongoDB Atlas M10 Cluster (auto-deployed by the
one-clickscript)
One-Click Deployment
The one-click.ksh Korn shell script automates the deployment of the MongoDB - Temporal Quickstart application on AWS infrastructure. It sets up the necessary AWS resources, deploys an EC2 instance, and configures the application environment.
Prerequisites
- AWS CLI installed and configured with appropriate credentials
- Access to a MongoDB Atlas account with necessary permissions
- Korn shell (ksh) environment
Script Structure
The script is organized into several main functions:
create_key(): Creates or uses an existing EC2 key pairdeploy_infra(): Deploys the base infrastructure using CloudFormationdeploy_ec2(): Deploys the EC2 instance and application stackread_logs(): Streams deployment logs from the EC2 instance- Main execution flow
Configuration
Environment Variables
AWS_ACCESS_KEY_ID: AWS access keyAWS_SECRET_ACCESS_KEY: AWS secret keyAWS_SESSION_TOKEN: AWS session token (if using temporary credentials)
Deployment Parameters
INFRA_STACK_NAME: Name for the infrastructure CloudFormation stackEC2_STACK_NAME: Name for the EC2 CloudFormation stackAWS_REGION: AWS region for deploymentEC2_INSTANCE_TYPE: EC2 instance type (e.g., "t3.xlarge")VolumeSize: EBS volume size in GBGIT_REPO_URL: URL of the application Git repositoryMongoDBClusterName: Name for the MongoDB Atlas clusterMongoDBUserName: MongoDB Atlas usernameMongoDBPassword: MongoDB Atlas passwordAPIPUBLICKEY: MongoDB Atlas API public keyAPIPRIVATEKEY: MongoDB Atlas API private keyGROUPID: MongoDB Atlas project IDTAVILY_API_KEY: Tavily Web Search API Key
Execution Flow
- Initialize logging
- Create or use existing EC2 key pair
- Deploy infrastructure CloudFormation stack
- Retrieve and store infrastructure stack outputs
- Deploy EC2 instance and application CloudFormation stack
- Start streaming EC2 deployment logs
- Monitor application URL until it becomes available
- Launch application URL in default browser
Functions
create_key() Creates a new EC2 key pair or uses an existing one with the name "MAAPTemporalKeyV1".
deploy_infra() Deploys the base infrastructure CloudFormation stack, including VPC, subnet, security group, and IAM roles.
deploy_ec2() Deploys the EC2 instance and application stack using a CloudFormation template. It includes the following steps:
- Selects the appropriate AMI ID based on the AWS region
- Creates the CloudFormation stack with necessary parameters
- Waits for stack creation to complete
- Retrieves and displays stack outputs
read_logs() Establishes an SSH connection to the EC2 instance and streams the deployment logs in real-time.
Logging
- Main deployment logs:
./logs/one-click-deployment.log - EC2 live logs:
./logs/ec2-live-logs.log
Error Handling
The script includes basic error checking for critical operations such as CloudFormation stack deployments. If an error occurs, the script will log the error and exit.
Security Considerations
- AWS credentials are expected to be set as environment variables
- MongoDB Atlas credentials and API keys are passed as CloudFormation parameters
Customization
To customize the deployment:
- Modify the CloudFormation template files (
deploy-infra.yamlanddeploy-ec2.yaml) - Adjust the deployment parameters at the beginning of the script
- Update the AMI IDs in the
ami_mapif newer AMIs are available
Troubleshooting
- Check the log files for detailed information on the deployment process
- Ensure all required environment variables and parameters are correctly set
- Verify AWS CLI configuration and permissions
- Check CloudFormation stack events in the AWS Console for detailed error messages
Limitations
- The script is designed for a specific application stack and may require modifications for other use cases
- It assumes a certain MongoDB Atlas and AWS account setup
- The script does not include rollback mechanisms for partial deployments. In case of partial failures, delete the related CloudFormation stacks from AWS Console.
Deployment Steps
- Clone the repository:
git clone <repository-url>
cd maap-temporal-qs - Configure the
one-click.kshscript: Open the script in a text editor and fill in the required values for various environment variables:- AWS Auth: Specify the
AWS_REGION,AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEYfor deployment. - EC2 Instance Types: Choose suitable instance types for your workload.
- Network Configuration: Update key names, subnet IDs, security group IDs, etc.
- Authentication Keys: Fetch Project ID, API public and private keys for MongoDB Atlas Cluster setup. Update the script file with the keys for
APIPUBLICKEY,APIPRIVATEKEY,GROUPIDsuitably.
- AWS Auth: Specify the
- Deploy the application:
chmod +x one-click.ksh
./one-click.ksh - Access the application at
http://<ec2-instance-ip>:7860
Post-Deployment Verification
- Access the UI service by navigating to
http://<ec2-instance-ip>:7860in your web browser. - Test the system by entering a query and verifying that you receive an appropriate AI-generated response.
- Try uploading a file to ensure the Loader Service is functioning correctly.
- Verify that the sample dataset bundled with the script is loaded into your MongoDB Cluster name
MongoDBTemporalV1under the databasetravel_agencyand collectiontrip_recommendationby visiting the MongoDB Atlas Console.
Manual Deployment
For manual deployment, follow these steps:
- Set up MongoDB Atlas Cluster:
./mongodb_cluster_manager.ksh deploy <cluster_name> <username> <password> - Create Vector Indexes:
./mongodb_create_vectorindex.ksh - Build Docker Images:
cd MAAP-Temporal
./build-images.ksh - Configure Environment Variables:
- Copy each service's sample.env to .env
- Fill in the required environment variables (see Configuration section)
- Deploy with Docker Compose:
docker-compose up -d
8. API Reference
FastAPI Application
POST /upload: Upload files and web URLs for processingPOST /log: Log messages to the centralized logging systemGET /health: Health check endpointPOST /conversation/: Add a message to the conversation history
MCP Server
/hybrid_search: Perform hybrid vector and keyword search on MongoDB collections/store_memory: Store conversation messages in AI memory/retrieve_memory: Retrieve relevant memories for context/semantic_cache_response: Cache AI responses for similar future queries/check_semantic_cache: Check for cached responses to similar queries
Semantic Cache Service
POST /save_to_cache: Save a query-response pair to the cachePOST /read_cache: Lookup a query in the semantic cache
Data Loader Service
POST /upload: Upload and process files or web URLs
Event Logger Service
POST /log: Log a messageGET /status: Get logger statusPOST /force-flush: Manually flush log buffer
For detailed API documentation, access the Swagger UI at http://<component-host>:<port>/docs.
9. Usage Flow
-
Document Ingestion:
- User uploads files or provides URLs
- Documents are processed and embedded
- Vector database is populated
-
User Query:
- User submits a query via UI
- System checks semantic cache for similar queries
- If no cache hit, system retrieves relevant memories and context
- AI generates a response using relevant context
- Response is stored in memory and cache
-
Memory Usage:
- System maintains a hierarchical memory structure
- Memories are reinforced or decay based on access patterns
- Important memories are preserved longer
- Similar memories are consolidated
-
Access the web interface:
- Enter a user ID to associate with your session
- Select the desired preprocessing workflows (semantic cache, AI memory, etc.)
- Type queries or upload files to interact with the AI system
- Use special commands:
- "refresh" to start a new conversation
- "image:/path/to/image.jpg Your query" to include images in your query
10. Error Handling and Logging
The system features:
- Centralized logging through the Event Logger service
- Structured logs with context information
- Local and remote log storage
- Error tracking and reporting
- Graceful failure handling through Temporal
Common issues and solutions:
-
Connection errors:
- Check MongoDB and AWS credentials in the configuration
- Verify network connectivity and service URLs in configuration
- Check security groups and firewall settings
-
Workflow failures:
- Review Temporal logs and ensure all required services are running
- Check workflow history in Temporal Web UI
- Verify all activities are properly registered
-
Image processing errors:
- Verify supported image formats and file permissions
- Check for sufficient disk space
- Ensure proper libraries are installed
-
Slow response times:
- Check semantic cache performance and consider adjusting similarity thresholds
- Monitor MongoDB performance and indexes
- Review AWS Bedrock service quotas
-
Authentication failures:
- Verify AWS and MongoDB credentials
- Check IAM roles and permissions
11. Security Considerations
Network and Firewall Configuration
MongoDB Atlas:
-
IP Access List:
- Restrict client connections to your Atlas clusters by configuring IP access lists.
- Add the public IP addresses of your application environments to the IP access list to permit access.
- For enhanced security, consider using VPC peering or private endpoints to allow private IP addresses.
- Configure IP Access List Entries.
-
Ports 27015 to 27017 (TCP):
- Ensure that your firewall allows outbound connections from your application environment to Atlas on ports 27015 to 27017 for TCP traffic.
- This configuration enables your applications to access databases hosted on Atlas.
AWS Services (e.g., Bedrock):
- Port 443 (HTTPS):
- Required for API calls and interactions.
- Configure security groups to allow outbound traffic on port 443.
- Ensure Network ACLs permit inbound and outbound traffic on this port.
Authentication and Authorization
-
Database Users:
- Atlas mandates client authentication to access clusters.
- Create database users with appropriate roles to control access.
- Configure Database Users.
-
Custom Roles:
- If default roles don't meet your requirements, define custom roles with specific privileges.
- Create Custom Roles.
-
AWS IAM Integration:
- Authenticate applications running on AWS services to Atlas clusters using AWS IAM roles.
- Set up database users to use AWS IAM role ARNs for authentication.
- AWS IAM Authentication.
Data Encryption
-
Encryption at Rest:
- Atlas encrypts all data stored on your clusters by default.
- For enhanced security, consider using your own key management system.
- Encryption at Rest.
-
TLS/SSL Encryption:
- Atlas requires TLS encryption for client connections and intra-cluster communications.
- Ensure your applications support TLS 1.2 or higher.
- TLS/SSL Configuration.
Network Peering and Private Endpoints
-
VPC Peering:
- Establish VPC peering between your AWS VPC and MongoDB Atlas's VPC to eliminate public internet exposure.
- Set Up a Network Peering Connection.
-
Private Endpoints:
- Use AWS PrivateLink to create private endpoints for secure communication within AWS networks.
- Configure Private Endpoints.
-
NAT Gateway:
- Use NAT Gateways to route traffic from private subnets while preventing direct internet access to EC2 instances.
-
Specific IP Ranges:
- AWS services like Bedrock use dynamic IPs. Filter these from AWS IP Ranges for egress traffic.
Compliance and Monitoring
-
Audit Logging:
- Enable audit logging to monitor database activities and ensure compliance with data protection regulations.
- Enable Audit Logging.
-
Regular Updates:
- Keep your dependencies and Docker images up to date to address security vulnerabilities.
12. Monitoring & Logging
The MAAP system includes a comprehensive logging solution:
-
Centralized Logging:
- All services log to the Logger Service
- Logs are stored in both files and MongoDB
-
Log Levels:
- DEBUG: Detailed debugging information
- INFO: General operational information
- WARNING: Warning events
- ERROR: Error events
- CRITICAL: Critical events
-
Log Retention:
- File logs are rotated daily and retained for 10 days
- MongoDB logs have a TTL index for automatic cleanup
-
Monitoring:
- Service health can be monitored via the Logger Service
- MongoDB Atlas provides monitoring for database operations
To access logs:
- View log files in the
logsdirectory of each service - Query the
event_logs.logscollection in MongoDB
13. Troubleshooting
Common issues and solutions:
-
Connection Issues:
- Problem: Services cannot connect to MongoDB
- Solution: Verify MongoDB URI, network connectivity, and whitelist IP addresses
-
Vector Index Errors:
- Problem: Vector search fails
- Solution: Run
mongodb_create_vectorindex.kshto recreate indexes
-
AWS Bedrock Access:
- Problem: Cannot access AWS Bedrock models
- Solution: Check AWS credentials and region configuration
-
Docker Compose Issues:
- Problem: Services fail to start
- Solution: Check logs with
docker-compose logsand ensure environment variables are set
-
Memory Issues:
- Problem: Services crash with out-of-memory errors
- Solution: Increase container memory limits in docker-compose.yml
-
Slow Response Times:
- Problem: System responses are slow
- Solution: Increase service replicas, check MongoDB performance, optimize vector indexes
14. Scalability Considerations
The system is designed for scalability:
- Microservices architecture allows independent scaling
- Temporal provides reliable workflow execution at scale
- MongoDB Atlas supports horizontal scaling
- Container-based deployment enables orchestration systems like Kubernetes
15. Development Guide
To contribute to the project:
- Set up a local development environment with Python 3.10+
- Use virtual environments for dependency management
- Follow Python best practices and PEP 8 style guidelines
- Implement unit tests for all components
- Use type hints and docstrings for better code readability and documentation
- Submit pull requests for code reviews before merging changes
To extend the system:
- Add new workflows in
workflows.py - Implement new activities in
activities.py - Extend the MCP server with new tools in
maap_mcp_server.py - Update the UI in
ui_app.pyto expose new functionalities - Follow existing patterns for error handling and logging
16. Maintenance & Operations
- Health check endpoints on all services
- Workflow status monitoring via Temporal UI
- Log analysis for error detection
- MongoDB performance monitoring
- Regularly backup MongoDB data and ensure proper retention policies
- Monitor and optimize MongoDB indexes for performance
- Keep Temporal workflows and activities up to date with the latest business logic
- Regularly review and update AI models and embeddings for improved performance
- Monitor AWS Bedrock usage and costs, adjusting as necessary
- Implement a log rotation policy to manage disk space usage
- Monitor system resource usage and scale as needed
- Implement automated alerts for critical errors or system issues
- Keep all dependencies and services up-to-date with the latest stable versions
- Regularly review and optimize performance bottlenecks
Conclusion
MongoDB - Temporal Quickstart provides a robust, scalable architecture for AI applications with advanced memory, caching, and document processing capabilities. By leveraging MongoDB Atlas for vector storage, Amazon Bedrock for AI, and Temporal for workflow orchestration, it offers a reliable foundation for building sophisticated AI applications with workflow reliability and data persistence.